CHI

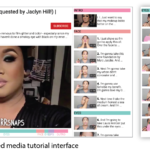
Paper in ACM CHI 2021 on “Automatic Generation of Two-Level Hierarchical Tutorials from Instructional Makeup Videos”
We present a multi-modal approach for automatically generating hierarchical tutorials from instructional makeup videos. Our approach is inspired by prior research in cognitive psychology, which suggests that people mentally segment procedural tasks into event hierarchies, where coarse-grained events focus on objects while fine-grained events focus on actions. In the instructional makeup domain, we find that objects correspond to facial parts while fine-grained steps correspond to actions on those facial parts. Given an input instructional makeup video, we apply a set of heuristics that combine computer vision techniques with transcript text analysis to automatically identify the fine-level action steps and group these steps by facial part to form the coarse-level events. We provide a voice-enabled, mixed-media UI to visualize the resulting hierarchy and allow users to efficiently navigate the tutorial (e.g., skip ahead, return to previous steps) at their own pace. Users can navigate the hierarchy at both the facial-part and action-step levels using click-based interactions and voice commands. We demonstrate the effectiveness of segmentation algorithms and the resulting mixed-media UI on a variety of input makeup videos. A user study shows that users prefer following instructional makeup videos in our mixed-media format to the standard video UI and that they find our format much easier to navigate.