Publications in 2021
Here is a list of my published work in 2021 with my excellent collaborators.
Apoorva Beedu, Zhile Ren, Varun Agrawal, Irfan Essa
VideoPose: Estimating 6D object pose from videos Technical Report
2021.
Abstract | Links | BibTeX | Tags: arXiv, computer vision, object detection, pose estimation
@techreport{2021-Beedu-VEOPFV,
title = {VideoPose: Estimating 6D object pose from videos},
author = {Apoorva Beedu and Zhile Ren and Varun Agrawal and Irfan Essa},
url = {https://arxiv.org/abs/2111.10677},
doi = {10.48550/arXiv.2111.10677},
year = {2021},
date = {2021-11-01},
urldate = {2021-11-01},
journal = {arXiv preprint arXiv:2111.10677},
abstract = {We introduce a simple yet effective algorithm that uses convolutional neural networks to directly estimate object poses from videos. Our approach leverages the temporal information from a video sequence, and is computationally efficient and robust to support robotic and AR domains. Our proposed network takes a pre-trained 2D object detector as input, and aggregates visual features through a recurrent neural network to make predictions at each frame. Experimental evaluation on the YCB-Video dataset show that our approach is on par with the state-of-the-art algorithms. Further, with a speed of 30 fps, it is also more efficient than the state-of-the-art, and therefore applicable to a variety of applications that require real-time object pose estimation.},
keywords = {arXiv, computer vision, object detection, pose estimation},
pubstate = {published},
tppubtype = {techreport}
}
Tianhao Zhang, Hung-Yu Tseng, Lu Jiang, Weilong Yang, Honglak Lee, Irfan Essa
Text as Neural Operator: Image Manipulation by Text Instruction Proceedings Article
In: ACM International Conference on Multimedia (ACM-MM), ACM Press, 2021.
Abstract | Links | BibTeX | Tags: computer vision, generative media, google, multimedia
@inproceedings{2021-Zhang-TNOIMTI,
title = {Text as Neural Operator: Image Manipulation by Text Instruction},
author = {Tianhao Zhang and Hung-Yu Tseng and Lu Jiang and Weilong Yang and Honglak Lee and Irfan Essa},
url = {https://dl.acm.org/doi/10.1145/3474085.3475343
https://arxiv.org/abs/2008.04556},
doi = {10.1145/3474085.3475343},
year = {2021},
date = {2021-10-01},
urldate = {2021-10-01},
booktitle = {ACM International Conference on Multimedia (ACM-MM)},
publisher = {ACM Press},
abstract = {In recent years, text-guided image manipulation has gained increasing attention in the multimedia and computer vision community. The input to conditional image generation has evolved from image-only to multimodality. In this paper, we study a setting that allows users to edit an image with multiple objects using complex text instructions to add, remove, or change the objects. The inputs of the task are multimodal including (1) a reference image and (2) an instruction in natural language that describes desired modifications to the image. We propose a GAN-based method to tackle this problem. The key idea is to treat text as neural operators to locally modify the image feature. We show that the proposed model performs favorably against recent strong baselines on three public datasets. Specifically, it generates images of greater fidelity and semantic relevance, and when used as a image query, leads to better retrieval performance.},
keywords = {computer vision, generative media, google, multimedia},
pubstate = {published},
tppubtype = {inproceedings}
}
Peggy Chi, Nathan Frey, Katrina Panovich, Irfan Essa
Automatic Instructional Video Creation from a Markdown-Formatted Tutorial Proceedings Article
In: ACM Symposium on User Interface Software and Technology (UIST), ACM Press, 2021.
Abstract | Links | BibTeX | Tags: google, human-computer interaction, UIST, video editting
@inproceedings{2021-Chi-AIVCFMT,
title = {Automatic Instructional Video Creation from a Markdown-Formatted Tutorial},
author = {Peggy Chi and Nathan Frey and Katrina Panovich and Irfan Essa},
url = {https://doi.org/10.1145/3472749.3474778
https://research.google/pubs/pub50745/
https://youtu.be/WmrZ7PUjyuM},
doi = {10.1145/3472749.3474778},
year = {2021},
date = {2021-10-01},
urldate = {2021-10-01},
booktitle = {ACM Symposium on User Interface Software and Technology (UIST)},
publisher = {ACM Press},
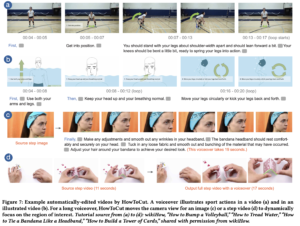
abstract = {We introduce HowToCut, an automatic approach that converts a Markdown-formatted tutorial into an interactive video that presents the visual instructions with a synthesized voiceover for narration. HowToCut extracts instructional content from a multimedia document that describes a step-by-step procedure. Our method selects and converts text instructions to a voiceover. It makes automatic editing decisions to align the narration with edited visual assets, including step images, videos, and text overlays. We derive our video editing strategies from an analysis of 125 web tutorials and apply Computer Vision techniques to the assets. To enable viewers to interactively navigate the tutorial, HowToCut's conversational UI presents instructions in multiple formats upon user commands. We evaluated our automatically-generated video tutorials through user studies (N=20) and validated the video quality via an online survey (N=93). The evaluation shows that our method was able to effectively create informative and useful instructional videos from a web tutorial document for both reviewing and following.},
keywords = {google, human-computer interaction, UIST, video editting},
pubstate = {published},
tppubtype = {inproceedings}
}
Karan Samel, Zelin Zhao, Binghong Chen, Shuang Li, Dharmashankar Subramanian, Irfan Essa, Le Song
Neural Temporal Logic Programming Technical Report
2021.
Abstract | Links | BibTeX | Tags: activity recognition, arXiv, machine learning, openreview
@techreport{2021-Samel-NTLP,
title = {Neural Temporal Logic Programming},
author = {Karan Samel and Zelin Zhao and Binghong Chen and Shuang Li and Dharmashankar Subramanian and Irfan Essa and Le Song},
url = {https://openreview.net/forum?id=i7h4M45tU8},
year = {2021},
date = {2021-09-01},
urldate = {2021-09-01},
abstract = {Events across a timeline are a common data representation, seen in different temporal modalities. Individual atomic events can occur in a certain temporal ordering to compose higher-level composite events. Examples of a composite event are a patient's medical symptom or a baseball player hitting a home run, caused distinct temporal orderings of patient vitals and player movements respectively. Such salient composite events are provided as labels in temporal datasets and most works optimize models to predict these composite event labels directly. We focus uncovering the underlying atomic events and their relations that lead to the composite events within a noisy temporal data setting. We propose Neural Temporal Logic Programming (Neural TLP) which first learns implicit temporal relations between atomic events and then lifts logic rules for composite events, given only the composite events labels for supervision. This is done through efficiently searching through the combinatorial space of all temporal logic rules in an end-to-end differentiable manner. We evaluate our method on video and on healthcare data where it outperforms the baseline methods for rule discovery. },
howpublished = {https://openreview.net/forum?id=i7h4M45tU8},
keywords = {activity recognition, arXiv, machine learning, openreview},
pubstate = {published},
tppubtype = {techreport}
}
Nathan Frey, Peggy Chi, Weilong Yang, Irfan Essa
Automatic Style Transfer for Non-Linear Video Editing Proceedings Article
In: Proceedings of CVPR Workshop on AI for Content Creation (AICC), 2021.
Links | BibTeX | Tags: computational video, CVPR, google, video editing
@inproceedings{2021-Frey-ASTNVE,
title = {Automatic Style Transfer for Non-Linear Video Editing},
author = {Nathan Frey and Peggy Chi and Weilong Yang and Irfan Essa},
url = {https://arxiv.org/abs/2105.06988
https://research.google/pubs/pub50449/},
doi = {10.48550/arXiv.2105.06988},
year = {2021},
date = {2021-06-01},
urldate = {2021-06-01},
booktitle = {Proceedings of CVPR Workshop on AI for Content Creation (AICC)},
keywords = {computational video, CVPR, google, video editing},
pubstate = {published},
tppubtype = {inproceedings}
}
AJ Piergiovanni, Anelia Angelova, Michael S. Ryoo, Irfan Essa
Unsupervised Discovery of Actions in Instructional Videos Proceedings Article
In: British Machine Vision Conference (BMVC), 2021.
Abstract | Links | BibTeX | Tags: activity recognition, computational video, computer vision, google
@inproceedings{2021-Piergiovanni-UDAIV,
title = {Unsupervised Discovery of Actions in Instructional Videos},
author = {AJ Piergiovanni and Anelia Angelova and Michael S. Ryoo and Irfan Essa},
url = {https://arxiv.org/abs/2106.14733
https://www.bmvc2021-virtualconference.com/assets/papers/0773.pdf},
doi = { https://doi.org/10.48550/arXiv.2106.14733},
year = {2021},
date = {2021-06-01},
urldate = {2021-06-01},
booktitle = {British Machine Vision Conference (BMVC)},
number = {arXiv:2106.14733},
abstract = {In this paper we address the problem of automatically discovering atomic actions in unsupervised manner from instructional videos. Instructional videos contain complex activities and are a rich source of information for intelligent agents, such as, autonomous robots or virtual assistants, which can, for example, automatically `read' the steps from an instructional video and execute them. However, videos are rarely annotated with atomic activities, their boundaries or duration. We present an unsupervised approach to learn atomic actions of structured human tasks from a variety of instructional videos. We propose a sequential stochastic autoregressive model for temporal segmentation of videos, which learns to represent and discover the sequential relationship between different atomic actions of the task, and which provides automatic and unsupervised self-labeling for videos. Our approach outperforms the state-of-the-art unsupervised methods with large margins. We will open source the code.
},
keywords = {activity recognition, computational video, computer vision, google},
pubstate = {published},
tppubtype = {inproceedings}
}
Harish Haresamudram, Irfan Essa, Thomas Ploetz
Contrastive Predictive Coding for Human Activity Recognition Journal Article
In: Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, vol. 5, no. 2, pp. 1–26, 2021.
Abstract | Links | BibTeX | Tags: activity recognition, IMWUT, machine learning, ubiquitous computing
@article{2021-Haresamudram-CPCHAR,
title = {Contrastive Predictive Coding for Human Activity Recognition},
author = {Harish Haresamudram and Irfan Essa and Thomas Ploetz},
url = {https://doi.org/10.1145/3463506
https://arxiv.org/abs/2012.05333},
doi = {10.1145/3463506},
year = {2021},
date = {2021-06-01},
urldate = {2021-06-01},
booktitle = {Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies},
journal = {Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies},
volume = {5},
number = {2},
pages = {1--26},
abstract = {Feature extraction is crucial for human activity recognition (HAR) using body-worn movement sensors. Recently, learned representations have been used successfully, offering promising alternatives to manually engineered features. Our work focuses on effective use of small amounts of labeled data and the opportunistic exploitation of unlabeled data that are straightforward to collect in mobile and ubiquitous computing scenarios. We hypothesize and demonstrate that explicitly considering the temporality of sensor data at representation level plays an important role for effective HAR in challenging scenarios. We introduce the Contrastive Predictive Coding (CPC) framework to human activity recognition, which captures the long-term temporal structure of sensor data streams. Through a range of experimental evaluations on real-life recognition tasks, we demonstrate its effectiveness for improved HAR. CPC-based pre-training is self-supervised, and the resulting learned representations can be integrated into standard activity chains. It leads to significantly improved recognition performance when only small amounts of labeled training data are available, thereby demonstrating the practical value of our approach.},
keywords = {activity recognition, IMWUT, machine learning, ubiquitous computing},
pubstate = {published},
tppubtype = {article}
}
Anh Truong, Peggy Chi, David Salesin, Irfan Essa, Maneesh Agrawala
Automatic Generation of Two-Level Hierarchical Tutorials from Instructional Makeup Videos Proceedings Article
In: ACM CHI Conference on Human factors in Computing Systems, 2021.
Abstract | Links | BibTeX | Tags: CHI, computational video, google, human-computer interaction, video summarization
@inproceedings{2021-Truong-AGTHTFIMV,
title = {Automatic Generation of Two-Level Hierarchical Tutorials from Instructional Makeup Videos},
author = {Anh Truong and Peggy Chi and David Salesin and Irfan Essa and Maneesh Agrawala},
url = {https://dl.acm.org/doi/10.1145/3411764.3445721
https://research.google/pubs/pub50007/
http://anhtruong.org/makeup_breakdown/},
doi = {10.1145/3411764.3445721},
year = {2021},
date = {2021-05-01},
urldate = {2021-05-01},
booktitle = {ACM CHI Conference on Human factors in Computing Systems},
abstract = {We present a multi-modal approach for automatically generating hierarchical tutorials from instructional makeup videos. Our approach is inspired by prior research in cognitive psychology, which suggests that people mentally segment procedural tasks into event hierarchies, where coarse-grained events focus on objects while fine-grained events focus on actions. In the instructional makeup domain, we find that objects correspond to facial parts while fine-grained steps correspond to actions on those facial parts. Given an input instructional makeup video, we apply a set of heuristics that combine computer vision techniques with transcript text analysis to automatically identify the fine-level action steps and group these steps by facial part to form the coarse-level events. We provide a voice-enabled, mixed-media UI to visualize the resulting hierarchy and allow users to efficiently navigate the tutorial (e.g., skip ahead, return to previous steps) at their own pace. Users can navigate the hierarchy at both the facial-part and action-step levels using click-based interactions and voice commands. We demonstrate the effectiveness of segmentation algorithms and the resulting mixed-media UI on a variety of input makeup videos. A user study shows that users prefer following instructional makeup videos in our mixed-media format to the standard video UI and that they find our format much easier to navigate.},
keywords = {CHI, computational video, google, human-computer interaction, video summarization},
pubstate = {published},
tppubtype = {inproceedings}
}
Dan Scarafoni, Irfan Essa, Thomas Ploetz
PLAN-B: Predicting Likely Alternative Next Best Sequences for Action Prediction Technical Report
no. arXiv:2103.15987, 2021.
Abstract | Links | BibTeX | Tags: activity recognition, arXiv, computer vision
@techreport{2021-Scarafoni-PPLANBSAP,
title = {PLAN-B: Predicting Likely Alternative Next Best Sequences for Action Prediction},
author = {Dan Scarafoni and Irfan Essa and Thomas Ploetz},
url = {https://arxiv.org/abs/2103.15987},
doi = {10.48550/arXiv.2103.15987},
year = {2021},
date = {2021-03-01},
urldate = {2021-03-01},
journal = {arXiv},
number = {arXiv:2103.15987},
abstract = {Action prediction focuses on anticipating actions before they happen. Recent works leverage probabilistic approaches to describe future uncertainties and sample future actions. However, these methods cannot easily find all alternative predictions, which are essential given the inherent unpredictability of the future, and current evaluation protocols do not measure a system's ability to find such alternatives. We re-examine action prediction in terms of its ability to predict not only the top predictions, but also top alternatives with the accuracy@k metric. In addition, we propose Choice F1: a metric inspired by F1 score which evaluates a prediction system's ability to find all plausible futures while keeping only the most probable ones. To evaluate this problem, we present a novel method, Predicting the Likely Alternative Next Best, or PLAN-B, for action prediction which automatically finds the set of most likely alternative futures. PLAN-B consists of two novel components: (i) a Choice Table which ensures that all possible futures are found, and (ii) a "Collaborative" RNN system which combines both action sequence and feature information. We demonstrate that our system outperforms state-of-the-art results on benchmark datasets.
},
keywords = {activity recognition, arXiv, computer vision},
pubstate = {published},
tppubtype = {techreport}
}
Vincent Cartillier, Zhile Ren, Neha Jain, Stefan Lee, Irfan Essa, Dhruv Batra
Semantic MapNet: Building Allocentric SemanticMaps and Representations from Egocentric Views Proceedings Article
In: Proceedings of American Association of Artificial Intelligence Conference (AAAI), AAAI, 2021.
Abstract | Links | BibTeX | Tags: AAAI, AI, embodied agents, first-person vision
@inproceedings{2021-Cartillier-SMBASRFEV,
title = {Semantic MapNet: Building Allocentric SemanticMaps and Representations from Egocentric Views},
author = {Vincent Cartillier and Zhile Ren and Neha Jain and Stefan Lee and Irfan Essa and Dhruv Batra},
url = {https://arxiv.org/abs/2010.01191
https://vincentcartillier.github.io/smnet.html
https://ojs.aaai.org/index.php/AAAI/article/view/16180/15987},
doi = {10.48550/arXiv.2010.01191},
year = {2021},
date = {2021-02-01},
urldate = {2021-02-01},
booktitle = {Proceedings of American Association of Artificial Intelligence Conference (AAAI)},
publisher = {AAAI},
abstract = {We study the task of semantic mapping -- specifically, an embodied agent (a robot or an egocentric AI assistant) is given a tour of a new environment and asked to build an allocentric top-down semantic map (`what is where?') from egocentric observations of an RGB-D camera with known pose (via localization sensors). Importantly, our goal is to build neural episodic memories and spatio-semantic representations of 3D spaces that enable the agent to easily learn subsequent tasks in the same space -- navigating to objects seen during the tour (`Find chair') or answering questions about the space (`How many chairs did you see in the house?').
Towards this goal, we present Semantic MapNet (SMNet), which consists of: (1) an Egocentric
Visual Encoder that encodes each egocentric RGB-D frame, (2) a Feature Projector that projects egocentric features to appropriate locations on a floor-plan, (3) a Spatial Memory Tensor of size floor-plan length × width × feature-dims that learns to accumulate projected egocentric features, and (4) a Map Decoder that uses the memory tensor to produce semantic top-down maps. SMNet combines the strengths of (known) projective camera geometry and neural representation learning. On the task of semantic mapping in the Matterport3D dataset, SMNet significantly outperforms competitive baselines by 4.01-16.81% (absolute) on mean-IoU and 3.81-19.69% (absolute) on Boundary-F1 metrics. Moreover, we show how to use the spatio-semantic allocentric representations build by SMNet for the task of ObjectNav and Embodied Question Answering.},
keywords = {AAAI, AI, embodied agents, first-person vision},
pubstate = {published},
tppubtype = {inproceedings}
}
Towards this goal, we present Semantic MapNet (SMNet), which consists of: (1) an Egocentric
Visual Encoder that encodes each egocentric RGB-D frame, (2) a Feature Projector that projects egocentric features to appropriate locations on a floor-plan, (3) a Spatial Memory Tensor of size floor-plan length × width × feature-dims that learns to accumulate projected egocentric features, and (4) a Map Decoder that uses the memory tensor to produce semantic top-down maps. SMNet combines the strengths of (known) projective camera geometry and neural representation learning. On the task of semantic mapping in the Matterport3D dataset, SMNet significantly outperforms competitive baselines by 4.01-16.81% (absolute) on mean-IoU and 3.81-19.69% (absolute) on Boundary-F1 metrics. Moreover, we show how to use the spatio-semantic allocentric representations build by SMNet for the task of ObjectNav and Embodied Question Answering.
- Categories
- Publications
- Tags
- Publications