Paper in ICLR 2022 on “Discrete Representations Strengthen Vision Transformer Robustness”
Citation
Abstract
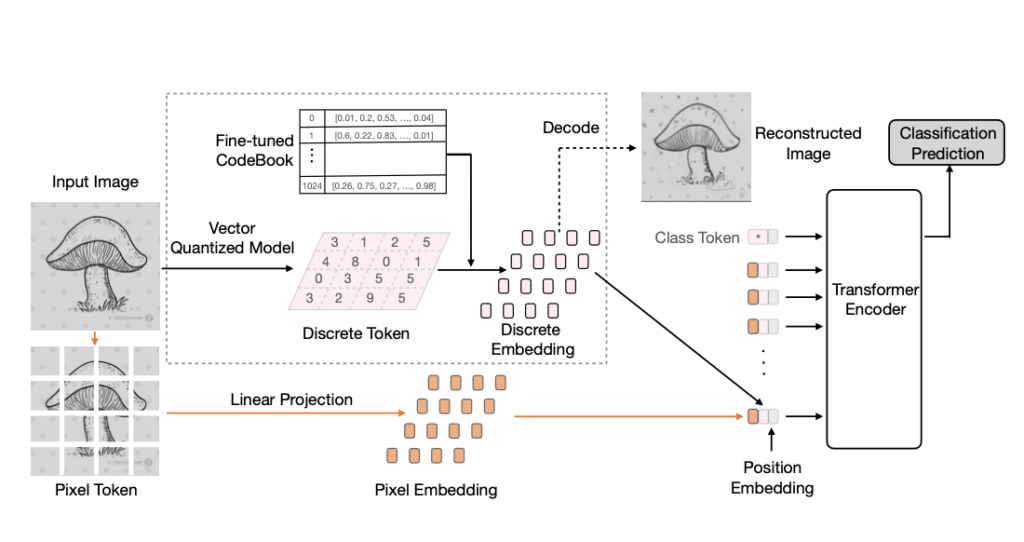
Vision Transformer (ViT) is emerging as the state-of-the-art architecture for image recognition. While recent studies suggest that ViTs are more robust than their convolutional counterparts, our experiments find that ViTs trained on ImageNet are overly reliant on local textures and fail to make adequate use of shape information. ViTs thus have difficulties generalizing to out-of-distribution, real-world data. To address this deficiency, we present a simple and effective architecture modification to ViT's input layer by adding discrete tokens produced by a vector-quantized encoder. Different from the standard continuous pixel tokens, discrete tokens are invariant under small perturbations and contain less information individually, which promote ViTs to learn global information that is invariant. Experimental results demonstrate that adding discrete representation on four architecture variants strengthens ViT robustness by up to 12% across seven ImageNet robustness benchmarks while maintaining the performance on ImageNet.
For slides and video presentations, go to the ICLR virtual presentations site.
Links
- https://iclr.cc/virtual/2022/poster/6647
- https://arxiv.org/abs/2111.10493
- https://research.google/pubs/pub51388/
- https://openreview.net/forum?id=8hWs60AZcWk
- doi:10.48550/arXiv.2111.10493
BibTeX (Download)
@inproceedings{2022-Mao-DRSVTR,
title = {Discrete Representations Strengthen Vision Transformer Robustness},
author = {Chengzhi Mao and Lu Jiang and Mostafa Dehghani and Carl Vondrick and Rahul Sukthankar and Irfan Essa},
url = {https://iclr.cc/virtual/2022/poster/6647
https://arxiv.org/abs/2111.10493
https://research.google/pubs/pub51388/
https://openreview.net/forum?id=8hWs60AZcWk},
doi = {10.48550/arXiv.2111.10493},
year = {2022},
date = {2022-01-28},
urldate = {2022-04-01},
booktitle = {Proceedings of International Conference on Learning Representations (ICLR)},
journal = {arXiv preprint arXiv:2111.10493},
abstract = {Vision Transformer (ViT) is emerging as the state-of-the-art architecture for image recognition. While recent studies suggest that ViTs are more robust than their convolutional counterparts, our experiments find that ViTs trained on ImageNet are overly reliant on local textures and fail to make adequate use of shape information. ViTs thus have difficulties generalizing to out-of-distribution, real-world data. To address this deficiency, we present a simple and effective architecture modification to ViT's input layer by adding discrete tokens produced by a vector-quantized encoder. Different from the standard continuous pixel tokens, discrete tokens are invariant under small perturbations and contain less information individually, which promote ViTs to learn global information that is invariant. Experimental results demonstrate that adding discrete representation on four architecture variants strengthens ViT robustness by up to 12% across seven ImageNet robustness benchmarks while maintaining the performance on ImageNet.},
keywords = {computer vision, google, machine learning, vision transformer},
pubstate = {published},
tppubtype = {inproceedings}
}

